SetFit is an approach for doing Few-Shot Learning that was developed by HuggingFace in collaboration with Intel and UKP Labs.
It is an alternative to PET that does not require prompts or verbalizers and it is relatively fast to train. It uses Contrastive Training to scale up the training set for multi-label classification problems.
Methodology
From the blog post:
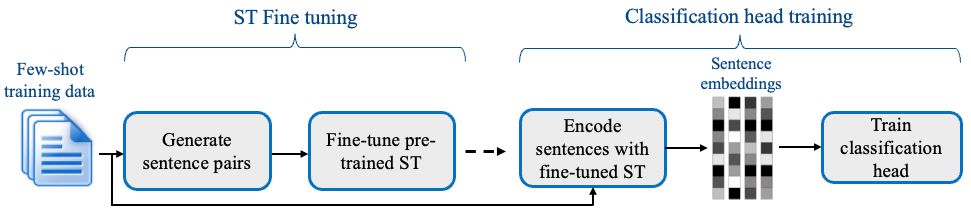
SetFit first fine-tunes a Sentence Transformer model on a small number of labeled examples (typically 8 or 16 per class). This is followed by training a classifier head on the embeddings generated from the fine-tuned Sentence Transformer.
Benchmark + Evaluation
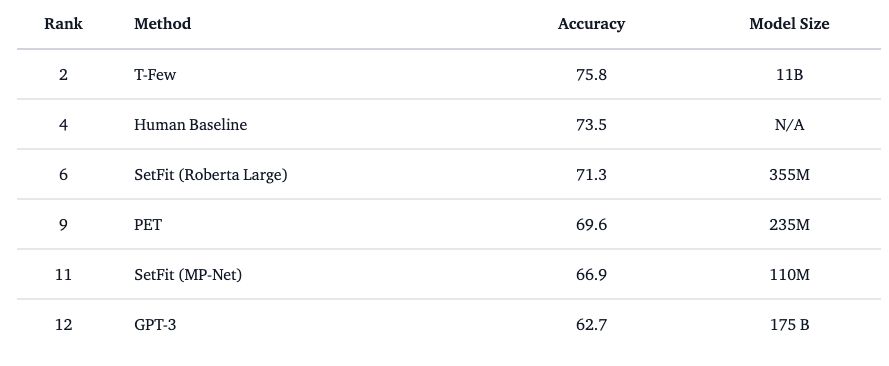
SetFit outperforms PET and GPT-3 - it is beaten by T-Few which is a model that is approx 100x bigger. It isn’t far off the human baseline for the benchmarked task on the RAFT leaderboard
SetFit and Python
We can easily train a SetFit model with a few lines of Python.
Installation
We need to install the library pip install setfit - this will pull in any further dependencies on pytorch, huggingface, sentence-transformer etc.
Training a SetFit model
Using the Huggingface dataset library and pandas we can take a CSV with text and label columns and use it to train and test setfit:
import pandas as pd
import numpy as np
from datasets import Dataset
from setfit import SetFitModel, SetFitTrainer, TrainingArguments, sample_dataset
TRAIN_TEST_FRAC = 0.7
labelled = pd.read_csv('path/to/your/data.csv')
# shuffle the dataset by randomly sampling all of it
# hard code random state.
shuffled = labelled.sample(frac=1.0, random_state=42)
# calculate the length of the test set
tlen = int(len(shuffled) * TRAIN_TEST_FRAC)
num_classes = len(shuffled['label'].unique())
train_df = pd.DataFrame(shuffled[:tlen])
test_df = pd.DataFrame(shuffled[tlen:])
train_ds = Dataset.from_pandas(train_df)
test_ds = train_ds = Dataset.from_pandas(test_df)
# Load SetFit model from Hub
#model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-mpnet-base-v2")
model = SetFitModel.from_pretrained('nomic-ai/nomic-embed-text-v1.5', trust_remote_code=True)
# Create trainer
trainer = SetFitTrainer(
model=model,
train_dataset=train_ds,
eval_dataset=test_ds,
batch_size=16,
num_iterations=20, # The number of text pairs to generate
column_mapping={"text":"text",'label':"label"}
)
# train the model
trainer.train()
We can then use the model to predict stuff:
example = "I am happy"
result = model.predict(examplee)We can also save the model for loading via from_pretrained next time:
model.save_pretrained("./models/setfit_classifier")Predicting with Confidence Scores:
We can use model.predict_proba() to get an array of label probabilities (after softmax) per input. We then need to map them back on to the known label:
results = trainer.model.predict_proba(
[
"10 ways your cat is spying on you",
"ACME Company announces bankruptsy after Wile E Coyote lawsuit"],
as_numpy=True
)
label_ids = np.argmax(results, axis=1)
result_labels = [ model.id2label[y] for y in label_ids]
results_scores = np.max(results, axis=1)
print(list(zip(result_labels, results_scores)))Multi-Label Training
As per the documentation we need to pass a multi_target_strategy argument when we load the base model. We also need to pass binarized labels as label in the training dataset which Argilla‘s prepare_dataset_for_training will do automatically.
from setfit import SetFitModel, SetFitTrainer, TrainingArguments, sample_dataset
model = SetFitModel.from_pretrained('WhereIsAI/UAE-Large-V1', trust_remote_code=True, multi_target_strategy='multi-output')
# Create trainer
trainer = SetFitTrainer(
model=model,
train_dataset=setfit_ds['train'],
eval_dataset=setfit_ds['test'],
batch_size=16,
num_iterations=20, # The number of text pairs to generate
column_mapping={"text":"text",'label':'legacy_label', 'binarized_label':"label"}
)Hyper Parameter Search
As per Phil Schmid’s blog post the setfit trainer has a hyper-parameter search system built in: